Executive Summary
The client uses an in-house Hadoop-based EMR pipeline using multi-VM cluster to process large data sets. The Customer has been using a traditional enterprise Big Data architecture with complex distributed self-managed tools which include clusters for Apache Spark, Zookeeper, HDFS, and HIVE.

Business Challenges
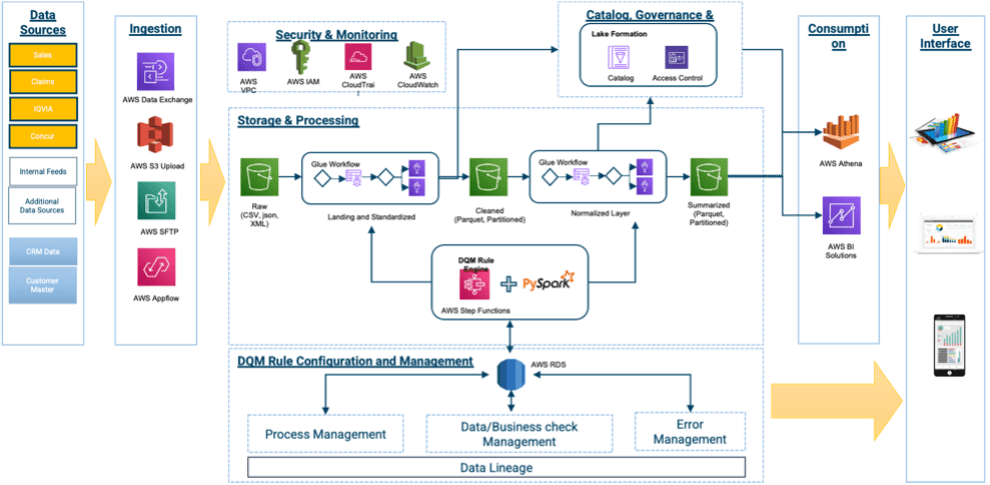
The customer is in the process of modernizing the data pipeline and move from a batch-based architecture to a more real time event-based architecture using cloud native technologies. The existing big data workflow of sourcing data into a datalake, ETL’ing data from source format to Parquet, and using a pre-trained Machine Learning model to predict based on the new data was running on high compute VMs that were required to run only few hours a day to validate a test after which the infrastructure was not required. Data is made available for user interaction via SQL queries. Managing all services and their uptime, triggering alerts and running it in cost effective way a key challenge.

Our Solution
The Sincera team decided to migrate this solution to AWS using cloud native event driven architecture. Our dataops and devops team were able to replicate the onprem architecture in a completely serverless approach. Additionally, using managed serverless components has enabled the client’s data team to overcome many of the problems and issues identified with the previous approach.
This serverless approach gives us the ability to:
- Query the data at any stage via AWS Athena
- Handle any errors or timeouts across the entire stack, route the error to a SNS topic, then onto any support team
- Configure retries at a per service or entire stack level.
- Inspect any file movement or service state via a simple query or HTTP request to DynamoDB
- Configure spark resources independently of each job, without worrying about cluster constraints or YARN resource sharing.
- Orchestrate stages neatly together in many ways (sequential, parallel, diverging)
Our team created Jenkins based devops pipeline to provision the solution.It is deployed in dev and prod environments. The pipeline is deisgned to build expensive resources on demand while letting the storage and data services running in all environments. This significantly brought down the costs tied to the solution.
Impact/ Key Benefits to the Client
- Increase development velocity and flexibility by splitting the Sourcing Lambda, Spark ETL, View Lambda, and Sagemaker Scripts into micro-service’s or monorepo’s
- Treat each ETL stage as a standalone service which only requires data in S3 as the interface between services.
- Recreate services quickly and reproducibly by leveraging tools such as Terraform.
- Create and manage workflows in a simple readable configuration language.
- Avoid managing servers, clusters, databases, replication, or failure scenario’s
- Reduce cloud spend and hidden maintenance costs by consuming resources as a service.
